에디터 노트 챗GPT 등 생성 인공지능(AI)을 쓰는 사람이 늘었습니다. 한국어로 자연스럽게 질문하고 답을 듣는 경우도 많은데요. 의외로 좀 어색한 답변을 받은 기억이 있을 겁니다. AI의 한국어 문장 이해도가 영어보다 낮아서일 수도 있지만, 학습 과정에서 데이터가 상대적으로 부족해 문화적 다양성을 습득하지 못했기 때문이기도 합니다. 이 사실은 혐오표현 등 AI 윤리 문제나 정보의 정확도, 양 등이 불균형 문제를 다루기 위해서도 중요합니다. 오혜연 KAIST 전산학부 교수가 설명합니다.
Pexels
챗GPT(ChatGPT)에게 한국에 사는 중학생이 추석을 어떻게 보내는지에 대해 쓰라고 했더니 다음과 같은 답변을 내뱉는다.
“드디어 추석 당일! 아침 일찍 일어나서 한복을 입고, 가족들과 함께 차례를 지낸다. 차례상에 올릴 음식들은 정성껏 준비됐고, 조상님께 감사의 마음을 전한다. 차례가 끝나면 온 가족이 모여 앉아 추석 음식을 나눠 먹는다. 전, 송편, 갈비찜 등 맛있는 음식들이 가득한 명절 음식이 항상 기다려진다. 오후에는 친척들과 함께 시간을 보낸다. 할아버지, 할머니 댁에 모여 사촌들과 놀기도 하고, 어른들께 세배를 드리며 용돈을 받기도 한다. 추석은 가족들이 한자리에 모일 수 있는 귀한 시간이어서 항상 즐겁다.”
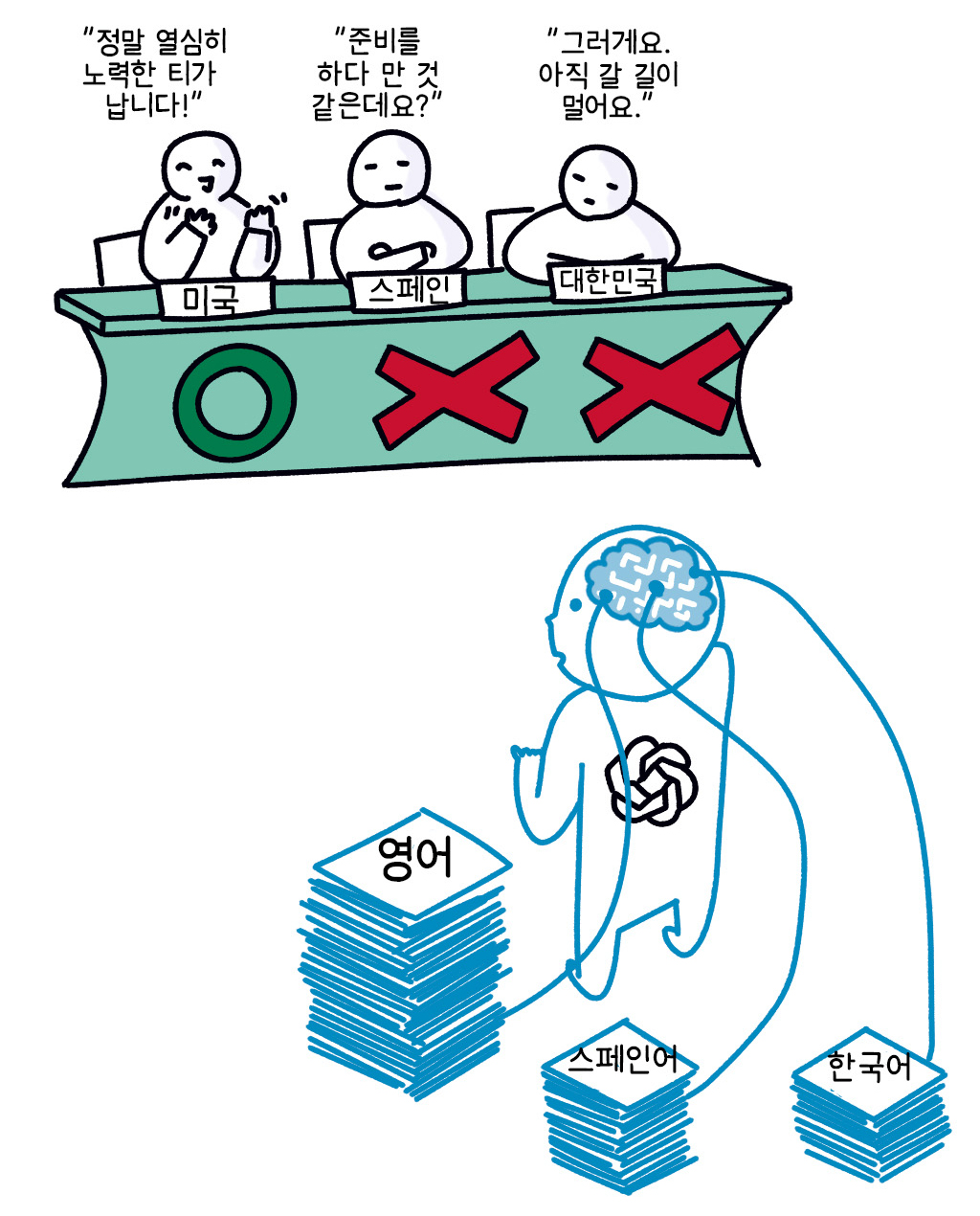
조금 이상한 답변이다. 세배는 설날에 하는 것이고, 중학생 중 “조상님께 감사의 마음을 전하는” 학생이 과연 몇이나 있을까? 유사한 질문들을 해 보니 챗GPT가 우리 문화에 대해 내놓는 답변은 상당히 어색하다 (그림 1). 반면 미국의 명절인 추수감사절에 대한 답변은, 중학교 시절부터 20여 년을 미국에서 보낸 필자가 보기에 문화적 이질감이 없다.
[그림 1] 챗GPT에게 한국의 문화와 관련한 질문을 해보면 어딘가 어색한 답변을 내놓을 때가 있다. 다양한 문화에 대한 이해가 아직 떨어지기 때문이다. 이솔
다중언어모델은 다양한 문화를 알까?
2022년 11월에 대중에게 공개된 오픈AI(OpenAI)의 챗GPT를 시작으로 앤트로픽(Anthropic)의 클로드(Claude), 메타의 라마(LLaMa), 구글의 제미나이(Gemini), 퍼플렉시티(Perplexity)의 퍼플렉시티 AI, 알리바바의 큐원(Qwen), 네이버의 하이퍼클로바X(HyperClovaX) 등 다양한 언어모델이 챗봇과 API* 형태로 공개되고 있다.
*API: 응용 프로그램 프로그래밍 인터페이스. 응용 프로그램에서 사용할 수 있도록, 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
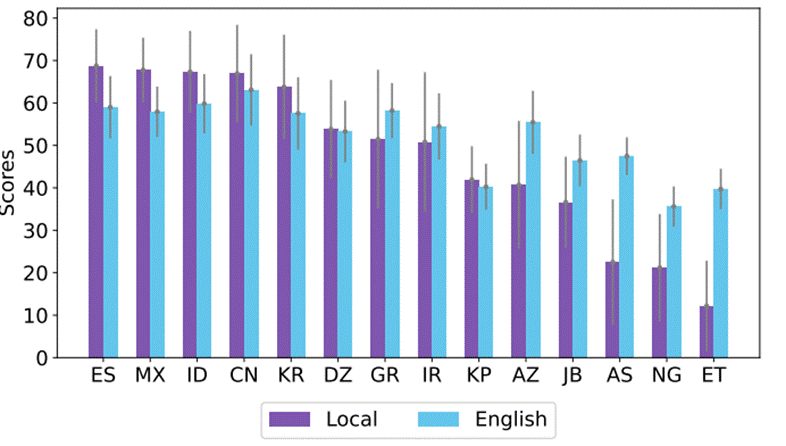
순식간에 많은 사람이 사용하게 된 이 모델들은 영어, 중국어, 한국어, 인도네시아어 등 다양한 언어를 지원하는 다중언어모델이 됐지만, 그 언어가 사용되는 다양한 문화권에 대한 이해는 현저히 떨어진다. 13개의 언어를 사용하는 16개 문화권에서 대형언어모델이 일상적인 상식을 묻는 질문에 얼마나 대답을 잘 하는지 평가하는 벤치마크 데이터셋인 BLEnD를 구축한 필자 연구팀의 최근 연구를 보자[1]. GPT-4를 포함한 최신 언어모델은 미국에 대한 질문에는 80% 이상의 정확도로 답을 하지만, 한국에 대해서는 65%, 에티오피아에 대해서는 50%도 안 되는 정확도를 보였다 (그림 2).
특히, 그래프에서 그리스 오른쪽에 있는 문화권의 경우, 현지 언어로 질문했을 때(보라색)보다 영어(하늘색)로 질문했을 때 오히려 정확도가 높아졌다. 언어모델들이 문화에 대한 상식이 낮을 뿐만 아니라, 현지 언어 능력도 낮다는 것으로 이해할 수 있다.
[그림 2] 다양한 문화권의 상식 문제에 대한 대형언어모델들의 평균 정확도[1]. (ES: 스페인, MX: 멕시코, ID: 인도네시아, CN: 중국, KR: 한국, DZ: 알제리, GR: 그리스, IR: 이란, KP: 북한, AZ: 아제르바이잔, JB: 인도네시아 서자와주, AS: 인도 아삼주, NG: 나이지리아, ET: 에티오피아)
챗GPT가 대중에게 공개된 지 채 2년이 안 된 시점이지만, 미디어, 의료, 법률, 금융, 교육 등 다양한 분야에 언어모델을 활용한 AI 에이전트가 활발히 연구, 개발되고 있다[2]. 특정 영역에서 사용되는 언어모델은 사용자 문화권의 상식을 제대로 알지 못하면 심각한 소통 장애가 생길 수 있다. 미국 의사가 한국 산모에게 회복을 빨리 하려면 치킨 수프를 먹으라고 권하는 것과 같다.
1언어 1문화?
그렇다면 언어모델이 가장 잘 하고, 학습 데이터도 충분하다고 하는 영어를 사용하는 국가에서는 언어모델의 문화 지식과 감수성이 사용자와 같은 수준일까. 영어는 국제공용어이기도 하지만 미국과 캐나다, 영국 이외에도 호주, 싱가포르, 남아프리카공화국, 인도 등 다양한 문화권에서 공용어나 국가언어로 사용되고 있다. 스페인어도 스페인, 멕시코, 콜롬비아를 포함한 20여 개국에서 사용되고, 국가의 공식언어가 없지만 영어가 사실상 공용어인 미국에서도 스페인어를 집에서 매일 사용하는 사람이 4000만 명이 넘는다. 한국어는 대한민국과 북한에서 사용된다. 세 언어만 보더라도 하나의 언어가 여러 문화권에서 사용된다는 것을 알 수 있다.
현대자동차를 북한에 가져간다고 생각해보자. 큰 불편함 없이 사용될 수 있을 것이다. 하지만 네이버가 만든 하이퍼클로바가 북한에서 쓰인다면 어떨까. 하이퍼클로바에게 맛집을 물어보면 파스타 레스토랑을 추천하고, 신혼여행지를 물어보면 국내에서는 제주도, 해외에서는 하와이나 발리를 소개한다. BLEnD 벤치마크를 만들 때 스페인어는 스페인과 멕시코, 한국어는 대한민국과 북한, 영어는 미국과 영국의 문화에 대해 답변을 각 나라에 사는 사람들로부터 얻었다(북한의 경우 북한이탈주민). 예상했던 대로 같은 언어를 사용하더라도 일상에 대한 질문에서는 답변이 다른 경우가 많았다.
결국, 하나의 언어가 하나의 문화를 대표한다고 보는 현재의 언어모델 개발에서의 가정은 틀렸다. 문화에 대한 상식과 감수성이 있는 언어모델을 만들기 위해서는 사용자들의 다양한 문화적 배경을 고려해야 한다 (그림 3).
[그림 3] 같은 언어권의 사람이라도 문화적 배경은 각각 다르다. 문화에 대한 상식과 감수성이 있는 언어모델을 만들기 위해서는 사용자들의 다양한 문화적 배경을 고려해야 한다. 이솔
인공지능 윤리와 문화
언어모델의 중요한 응용사례 중 하나인 혐오표현 감지기는 소셜미디어에서 인종, 성별, 종교 등의 다양한 집단에 대한 혐오발언을 걸러주는 역할을 한다. 여기에서도 문화적 차이가 크게 나타나는데, 영어 혐오발언 데이터셋을 한국어로 번역해서 한국어 혐오발언 탐지기를 돌려보면 76% 이상이탐지가 안 된다[3].
반대의 경우도 많아서, 한국어 혐오표현을 영어로 번역하면 혐오표현이 아니라고 나온다. 실제로 미국인의 관점에서 혐오표현이 아니어서가 아니다. 최근 한국에서 혐오표현에 종종 거론되는 중국인, 조선족 등은 미국에서는 혐오표현에 거론되지 않고, 미국에서의 혐오표현에 종종 거론되는 유대인, 라틴아메리카인 등은 한국 소셜미디어에서 거의 거론되지 않기 때문이다.
영어를 집중적으로 살펴보기 위해 영국, 호주, 싱가포르, 남아프리카공화국에 거주하는 사람을 통해 영어 혐오표현을 수집했더니, 모든 나라에서 나머지 나라와는 다른 혐오표현이 수집됐고, 같은 표현을 두고 혐오 여부에 대한 의견이 크게 엇갈렸다[4]. 최신 언어모델이 각 나라의 혐오표현을 걸러낼 수 있는지 봤더니, 싱가포르의 경우 73% 정도의 정확도를 기록해, 미국이나 영국의 80%보다 현저히 낮다는 것을 확인할 수 있었다. 예상했던 대로, 거대언어모델이 이해하고 생성하는 언어는 북미의 문화권의 데이터로 학습했다 (그림 4).
[그림 4] 거대언어모델이 이해하고 생성하는 언어는 북미의 문화권의 데이터로 주로 학습했고, 이 때문에 다양한 문화권을 이해하는 데 약점을 드러낸다. 이솔
팩트와 문화
언어모델이 얼마나 정확한 답변을 하는지, 사실성(factuality)에 대한 연구도 매우 중요하고 활발한 분야다. 특정 인물에 대해 영어로 질문한 뒤, 응답을 해당 인물의 위키백과 문서와 비교하면 참인 정보와 거짓인 정보의 비율을 알 수 있다. 이 비율을 팩트스코어(FactScore)라고 정의하고 그 결과를 발표했다[5]. 이 연구에 따르면, 인터넷에 많이 나오는 인물일수록 팩트스코어가 높아졌으며, 이런 인물은 대부분 미국이나 유럽의 배우 또는 정치인이었다.
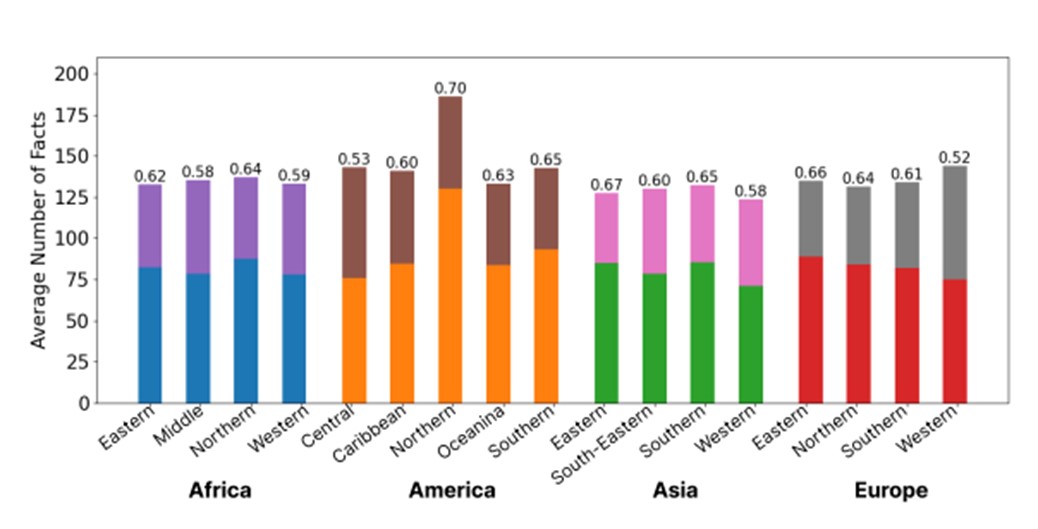
인물에 대한 질문을 전 세계로 넓혀 보면 언어모델들의 팩트스코어가 어떻게 나타날까. 이 질문에 대한 답을 확인하는 연구가 올해 10월에 발표된다[6]. 대륙마다 인구가 가장 많은 20개 나라의 리더(대통령, 총리 등)에 대해 언어모델에 물어보고 위키백과에 나와 있는 정보와 비교해 봤다. 여러 언어로 시험했지만, 그 가운데 가장 정확도가 높은 영어를 대상으로 한 분석 결과를 보면, 북미의 리더에 대해 가장 긴 답변을 하고 팩트스코어도 높았다.
반면 나머지 지역에 대해서는 현저히 낮았다 (그림 5). 예를 들어, 박근혜 전 대통령에 대해 얘기해 달라고 하자 약 120개의 정보 단위(예를 들어 “1952년생”)를 포함한 답변을 했는데, 그 중 참은 약 80개였고, 나머지 약 40개가 거짓이었다. 이는 오바마 전 미국 대통령에 대해 물어본 결과 약 180개의 정보가 답변에 들어 있고 그 중 126개 정도가 참이었던 것과 비교된다.
[그림 5] 각 나라의 리더에 대한 언어모델의 답변 중 참(아래부분)과 거짓(위부분) 정보의 비율 [6]
앞으로 점점 더 많은 정보를 언어모델을 통해 접하게 될 것이다. 주관성이 큰 혐오표현도 문제지만, 인물 정보를 물어봤을 때 지역에 따라 정확도나 정보의 양 차이가 크다는 것도 매우 중요하고 심각한 문제가 될 것이다.
문화적 감수성 가르치기
연구자들이 언어모델의 문화적 지식과 감수성에 대해 활발히 연구하기 시작한지 아직 2년이 채 되지 않았다. 대형언어모델도 2022년에야 처음 공개됐다. 현재 쓰이는 트랜스포머 기반의 BERT 모델이 구글에서 처음 나온 시점까지 따져도 겨우 2017년부터다. 어쩌면 지역별 문화적 감수성을 아직 갖추지 못한 게 당연하다. 언어모델 학습데이터를 만들 때에 문화 차이에 대한 고려가 전혀 없었고, 그 결과 영어의 경우 북미와 영국의 문화만 학습됐다고 볼 수 있다. 수능, SAT(미국 대입 시험)와 같이 정보의 정확함을 측정하는 검증에만 집중했기에, 문화적 상식과 감수성이 있는지는 문제 의식 자체가 없었다.
AI 에이전트가 트렌드가 되고 있다. AI의 대표적 기술인 대형언어모델과 그로부터 나온 챗봇의 문화적 감수성을 훈련시키는 연구가 시급하다.
글 오혜연 KAIST 전산학부 교수
그림 이솔 과학일러스트레이터·약사
기획 사단법인 집현네트워크 기획 최기영 전 서울대 교수, 전 과학기술정보통신부 장관 편집 윤신영 alookso 에디터
이 프로그램은 과학기술진흥기금 및 복권기금의 재원으로 운영되고 과학기술정보통신부와 한국과학창의재단의 지원을 받아 수행된 성과물로 우리나라의 과학기술 발전과 저소득 소외계층의 복지 증진에도 기여하고 있습니다.




















.jpg)


