






메타의 '라마(LLaMA)' 유출, 정말 실수였을까?

2023/05/30
메타의 라마(LLaMA) 유출
지난 2023년 3월 3일 연구용으로만 개방됐던 메타(구 페이스북)의 대규모 언어모델(LLM, Large Language Model) 라마(LLaMA)가 일반인들에게 유출되는 사고가 있었습니다.
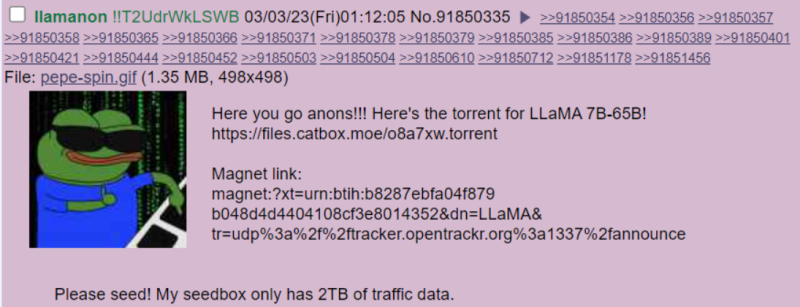
최초 유포자는 익명 커뮤니티 포찬(4chan)에 라마 다운로드용 토렌트 링크를 공유했는데, 이 과정에서 고유 식별 코드를 남기는 실수를 범했습니다. 그러나 메타에서 이를 인지했음에도 며칠 동안 별다른 조치를 하지 않은 것으로 알려졌습니다.
더 나아가 유출된 라마의 매개 변수 개수 별(7B / 13B / 30B / 65B) 가중치 데이터를 40MB/s로 다운로드할 수 있는 링크가 GitHub에 게시되면서 퍼지는 속도가 증폭되었습니다.
라마 유출 그 이후
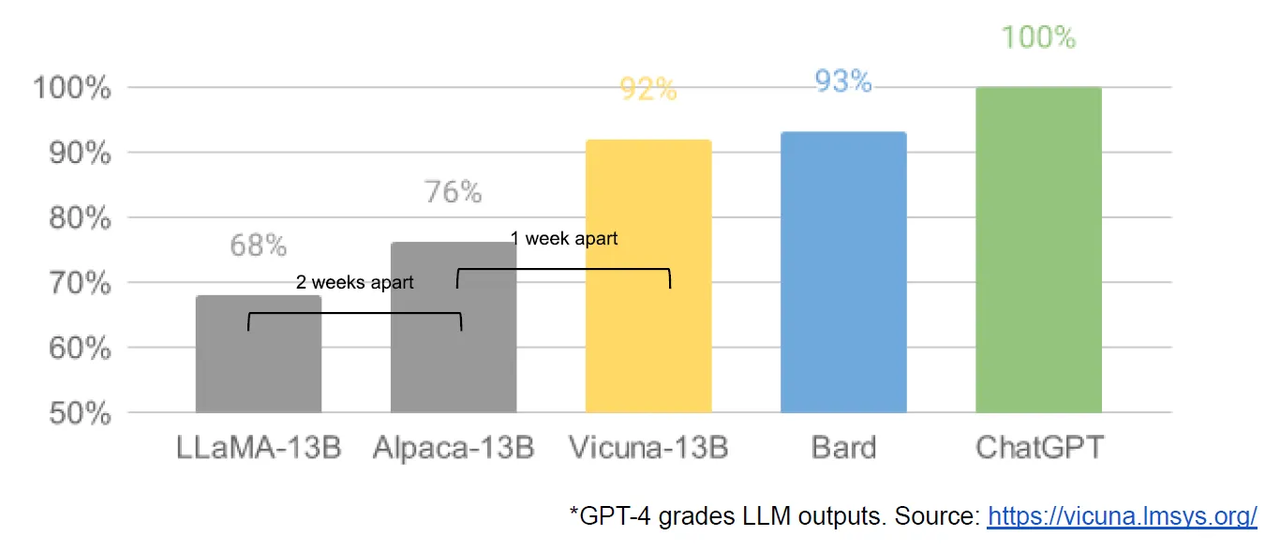
그로부터 2개월이 지난 지금, 유출된 '라마'를 기반으로 훈련한 '알파카', '비쿠냐'의 성능이 라마를 한참 뛰어넘은 것은 물론 'ChatGPT'와 'Bard'에 근접한 수준이라는 것이 알려졌습니다.









.jpg)



@김재경 메타에서 상업화 요구에 대해 '아직 준비가 되지 않았다'라고 말한 부분이 AI에 대한 통제가 준비가 되어있지 않다는 뜻으로 해석할 수 있을 것 같습니다.
말씀하신 것 처럼 범지구적으로 AI의 규제가 논의되고 있는 상황에서 섣불리 상업화를 시도하지는 않을 것으로 예상되지만, '언젠가는 되지 않을까?' 라는 기대감으로 적어보았습니다. 고견 감사합니다 :)
언젠가는 공개할 수 있겠지만, 그래도 ai에 대해 규제가 필요하다는 지금의 흐름에는 역행할 것으로 보입니다. 실제로 통제가 어려워질 수 있기 때문에 상업적 이유로는 공개하고 있지 않은 것으로 보인다는 의견도 있구요. https://www.aitimes.com/news/articleView.html?idxno=151202
다만 본문에 작성해 주신대로, 업계 점유율 향상을 고려하면 의도적으로 공개했을 거라는데에 저도 동의합니다.
@김재경 메타에서 상업화 요구에 대해 '아직 준비가 되지 않았다'라고 말한 부분이 AI에 대한 통제가 준비가 되어있지 않다는 뜻으로 해석할 수 있을 것 같습니다.
말씀하신 것 처럼 범지구적으로 AI의 규제가 논의되고 있는 상황에서 섣불리 상업화를 시도하지는 않을 것으로 예상되지만, '언젠가는 되지 않을까?' 라는 기대감으로 적어보았습니다. 고견 감사합니다 :)
언젠가는 공개할 수 있겠지만, 그래도 ai에 대해 규제가 필요하다는 지금의 흐름에는 역행할 것으로 보입니다. 실제로 통제가 어려워질 수 있기 때문에 상업적 이유로는 공개하고 있지 않은 것으로 보인다는 의견도 있구요. https://www.aitimes.com/news/articleView.html?idxno=151202
다만 본문에 작성해 주신대로, 업계 점유율 향상을 고려하면 의도적으로 공개했을 거라는데에 저도 동의합니다.