








2022/02/21
사실 단순 검색어 숫자로 지지율을 분석할 수는 없겠죠(심지어 미국의 선거제도는 시민들의 득표수를 직접 비교하는게 아닌 선거인단을 선출하는 방식이니까.. 기존에는 이를 간접선거로 표현했지만 정치학에서 이를 직접선거로 봐야한다는 의견도 갈립니다).
오히려 검색량이 많을 때 지지율이 하락할 이유인, 부정적인 이슈가 포함되어 있을 가능성이 있죠.
오히려 검색량이 많을 때 지지율이 하락할 이유인, 부정적인 이슈가 포함되어 있을 가능성이 있죠.
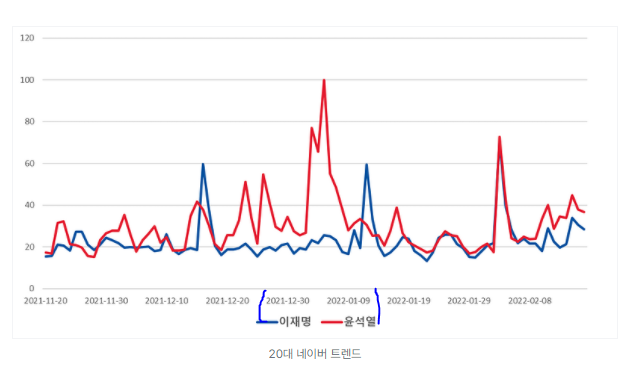

실제로 네이버 트렌드(네이버 데이터랩 맞나요?) 검색량 추이에서 가장 윤석열과 이재명 후보의 검색량 차이가 윤석열 후보가 많은 쪽으로 났던 시기에, 가장 압도적으로 이재명 후보가 윤석열 후보를 앞서고 있음을 볼 수 있습니다.
이를 증명하는 방법으로는 신문 기사 텍스트 분석이 유효합니다. 기사들에서 많이 나오는 단어를 분석해서 어떤 내용이 포함되어 있는지 보는 것이죠. 원래는 파이썬이나 R과 같은 소프트웨어를 통해 텍스트를 직접 분석해야 하지만, 한국 신문기사 한정으로는 대...
이를 증명하는 방법으로는 신문 기사 텍스트 분석이 유효합니다. 기사들에서 많이 나오는 단어를 분석해서 어떤 내용이 포함되어 있는지 보는 것이죠. 원래는 파이썬이나 R과 같은 소프트웨어를 통해 텍스트를 직접 분석해야 하지만, 한국 신문기사 한정으로는 대...



인공지능, 정치과정, 국제정치, 사회 시사 이슈 등 다루고 싶은 걸 다룹니다.
기술과 사회에 관심이 많은 연구활동가(Activist Researcher)입니다.
연구, 협업 등 문의 tofujaekyung@gmail.com
.png)







1월 전후의 국민의힘의 문제와 그에 따른 검색 동향을 보니 선거가 관심과 응원의 포지티브 선거가 아니라, 네거티브 선거 양상이 될 경우에는, 많은 검색량이 오히려 나쁜 신호일 수도 있겠네요.
좀 더 상세한 분석을 하고자 R과 파이썬을 걸음마 단계로 공부중인데.. 사실 아직 구체적인 분석 방법도 잘 모르긴 합니다 ㅋㅋㅋㅋㅋㅋ(막 텍스트군별로 상위 10% 하위10% 빈도 단어 제외하고 하는 방법이라던가.. 머신러닝 활용하는 텍스트 분석도 종류가 많아서). 문제제기를 먼저 해주시고, 자료도 잘 모아와 주신 만큼 제 글이 답글이라고 생각합니다 ㅎㅎ 좋은 글 잘 보고 가요!
간단하게 분석한 제 글보다 훨씬 더 밀도있는 분석을 해주셨네요. 이 글이 본체고 저의 원래 글이 답글인 것 같습니다ㅎㅎ
빅카인즈에서는 각 후보명 검색으로 나오는 신문기사들의 토큰화된 명사나 주제어들이 데이터로 나올겁니다. 전체를 다 토픽모델링으로 주제분류를 한 다음에 각 시기별로 어떤 주제가 나오는 것인지를 보면, 언론의 흐름을 각 후보별로 압축적으로 볼 수 있을 것 같습니다.
구글 데이터와 빅카인즈데이터의 연계는 직접적으로는 못 할 수도 있을 것 같아보입니다만, 빅카인즈를 이용한 토픽모델링 결과를 해석하는데에는 사용할 수 있을 것 같습니다.
시간이 허락할 때 자주 사용되는 LDA 같은 것으로 일단 탐색적으로 토픽모델링을 한 번 해보는 것도 좋을 것 같습니다.
※ 말씀대로 네이버 데이터랩이 맞습니다.
간단하게 분석한 제 글보다 훨씬 더 밀도있는 분석을 해주셨네요. 이 글이 본체고 저의 원래 글이 답글인 것 같습니다ㅎㅎ
빅카인즈에서는 각 후보명 검색으로 나오는 신문기사들의 토큰화된 명사나 주제어들이 데이터로 나올겁니다. 전체를 다 토픽모델링으로 주제분류를 한 다음에 각 시기별로 어떤 주제가 나오는 것인지를 보면, 언론의 흐름을 각 후보별로 압축적으로 볼 수 있을 것 같습니다.
구글 데이터와 빅카인즈데이터의 연계는 직접적으로는 못 할 수도 있을 것 같아보입니다만, 빅카인즈를 이용한 토픽모델링 결과를 해석하는데에는 사용할 수 있을 것 같습니다.
시간이 허락할 때 자주 사용되는 LDA 같은 것으로 일단 탐색적으로 토픽모델링을 한 번 해보는 것도 좋을 것 같습니다.
※ 말씀대로 네이버 데이터랩이 맞습니다.
1월 전후의 국민의힘의 문제와 그에 따른 검색 동향을 보니 선거가 관심과 응원의 포지티브 선거가 아니라, 네거티브 선거 양상이 될 경우에는, 많은 검색량이 오히려 나쁜 신호일 수도 있겠네요.
좀 더 상세한 분석을 하고자 R과 파이썬을 걸음마 단계로 공부중인데.. 사실 아직 구체적인 분석 방법도 잘 모르긴 합니다 ㅋㅋㅋㅋㅋㅋ(막 텍스트군별로 상위 10% 하위10% 빈도 단어 제외하고 하는 방법이라던가.. 머신러닝 활용하는 텍스트 분석도 종류가 많아서). 문제제기를 먼저 해주시고, 자료도 잘 모아와 주신 만큼 제 글이 답글이라고 생각합니다 ㅎㅎ 좋은 글 잘 보고 가요!