


liw3992





[과학 학술저널 이야기] 3. 프리프린트와 오픈 사이언스는 저널의 대안이 될 수 있는가
[과학 학술저널 이야기] 3. 프리프린트와 오픈 사이언스는 저널의 대안이 될 수 있는가
프리프린트
사실 논문을 작성하여 저널에 투고하기 전 논문 원고를 동료 학자들에게 보내 회람하여 코멘트를 듣는 일은 현재의 ‘프리프린트’ 라는 단어가 일반화되기 전부터 흔한 일이었다. 가령 로절린드 프랭클린은 DNA 연구를 접고 담배 모자이크 바이러스 연구를 해서 논문을 투고하기 전에 프랜시스 크릭이나 왓슨과 같은 사람들에게 초고를 보여주고 코멘트를 들었으며, 다른 과학자들도 마찬가지였다. 1960년대에는 미국 국립보건원을 중심으로 하여 출판전 원고를 회람하는 ‘정보 교환 그룹’ (Information Exchange Group, IEG) 이라는 모임이 존재하기도 하였다. (IEG는 1960년대 말, 당시 세력을 키워가던 상업 출판사 및 저널을 발행하는 학회의 반발에 의해 없어졌다. 이들은 출판 이전에 공개된 원고는 출판하지 않는다는 규칙을 세워 과학자들의 원고 공개 회람을 막았다)
그러나 지금과 같은 형식의 프리프린트는 인터넷의 탄생과 직접적으로 연관되어 있다. 1980...

DNA 이중나선 70년, 신화와 오해 - 왓슨/크릭은 프랭클린의 데이터를 훔친 것이 아니다
DNA 이중나선 70년, 신화와 오해 - 왓슨/크릭은 프랭클린의 데이터를 훔친 것이 아니다
지금으로부터 70년 전, 1953년 4월 25일 네이처에는 3개의 논문이 백투백 (논문이 저널의 같은 호에 이어서 실리는 것) 으로 실렸다. 첫번째 논문은 캠브리지 대학의 왓슨과 크릭, 두번째는 런던 킹스 칼리지의 윌킨스,스토크스,윌슨의 논문, 세번째는 킹스 칼리지의 프랭클린과 고슬링의 논문이다.
왓슨, 크릭의 논문
윌킨스, 스토크스, 윌슨의 논문
프랭클린 & 고슬링의 논문
이 논문은 다름아닌 DNA 이중 나선의 모델과 이를 입증하는 실험 데이터에 관련된 논문이다. 학술지에 논문을 내본 사람이라면 알겠지만, 저널에 논문을 이렇게 백투백으로 내는 것은 비슷한 연구를 하던 연구자들이 비슷한 결론에 도달했을때, 사전에 합의하여 연구의 우선권을 공평하게 가지도록 (과학 연구에서 언제나 우선권은 제일 먼저 논문을 발표한 사람들에게 있으므로) 하는 관행이고, 실제로 이 논문들은 사전에 캠브리지 대학과 킹스 칼리지의 관련 연구자들에 의해 협의되어 나온 논문들이다.
이 논문...

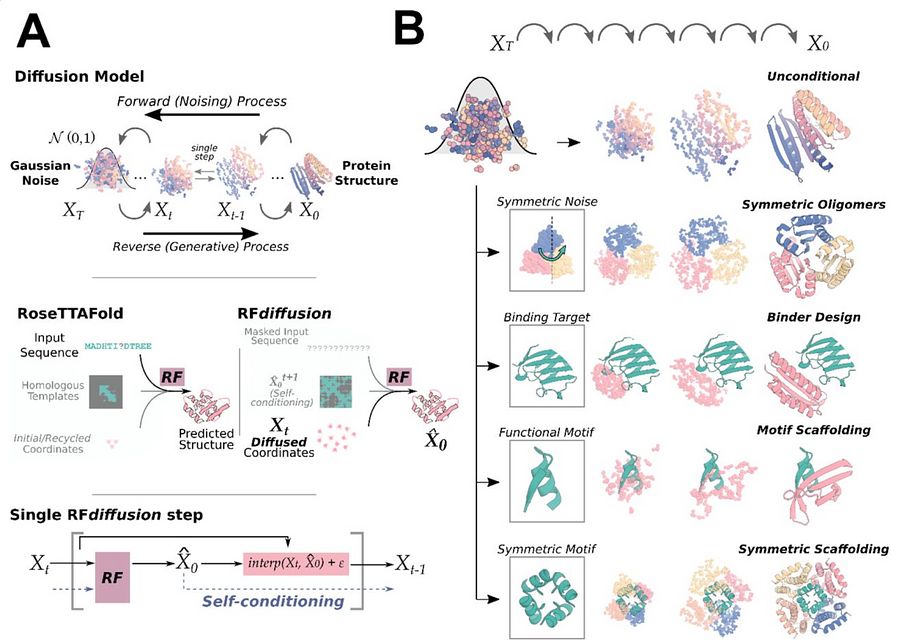
[누구나 해보는 단백질 디자인] 3. 다른 단백질에 들러붙는 단백질 만들기

[누구나 해보는 단백질 디자인] 2. 인공 단백질에 기능을 불어넣기

[누구나 해보는 단백질 디자인] 1. 자연계에 존재하지 않는 단백질 만들기

[학술 연구자를 위한 ChatGPT 활용] 3. ChatGPT 로 논문 읽기와 피어 리뷰 흉내
[학술 연구자를 위한 ChatGPT 활용] 3. ChatGPT 로 논문 읽기와 피어 리뷰 흉내
지난 연재에서는 의생명과학 학술 논문의 초록을 외부 데이터베이스에서 검색하고, 이를 기반으로 논문 형식의 글을 쓰는 방법을 알아보았다. 이번에는 논문을 ChatGPT 를 이용하여 ‘읽는’ 방법에 대해서 알아보도록 하자. 여기서 학술 논문을 읽는다는 것은 논문에서 제시한 내용을 이해하는 것을 넘어서, 논문의 핵심 주장을 파악하고, 이를 비판적으로 읽는 과정을 의미한다.
대부분의 출판물과 학술논문이 가지는 큰 차이라면 오늘날 거의 대부분의 학술 논문은 출판 전에 해당 분야 연구자에 의한 ‘피어 리뷰’ (동료 평가로 번역하는 것이 제일 적절하다) 를 거치고 여기서 나온 지적이나 비판을 보완하는 과정을 거친 이후에야 출판된다. 학계에서 권위가 있는 저널인 경우에는 내가 작성한 논문이 이러한 권위에 걸맞는 존재인지, 즉 논문 연구주제의 독창성과 연구 수행 방법의 엄밀성에 대해서 피어 리뷰를 통하여 혹독히 도전받는다. 그리하여 상당수의 논문들은 이러한 피어 리뷰의 문턱을 넘지도 못하...

[학술 연구자를 위한 ChatGPT 활용] 2. 맥락이 풍부해질수록 단단해지는 ChatGPT의 결과물
[학술 연구자를 위한 ChatGPT 활용] 2. 맥락이 풍부해질수록 단단해지는 ChatGPT의 결과물
지난번의 글에서는 ChatGPT와 같은 거대 언어 모델에 기반한 도구는 검색 엔진과는 판이하게 다르며, 학술 관련 글과 같이 디테일이 정확해야 하는 글에서는 거대 언어 모델에서 나오는 결과물은 여러가지 방법을 통해서 팩트체크를 거쳐야 한다는 이야기를 했다.
이번에는 지난번과는 다른 관점에서 ChatGPT 를 이용하여 보다 근거에 기반한 글을 생성할 수 있는 방법에 대해서 알아보도록 한다. 이를 위해서는 과연 ChatGPT 가 어떻게 사용자와 "대화" 를 하는지에 대해서 잠시 알아보기로 하자.
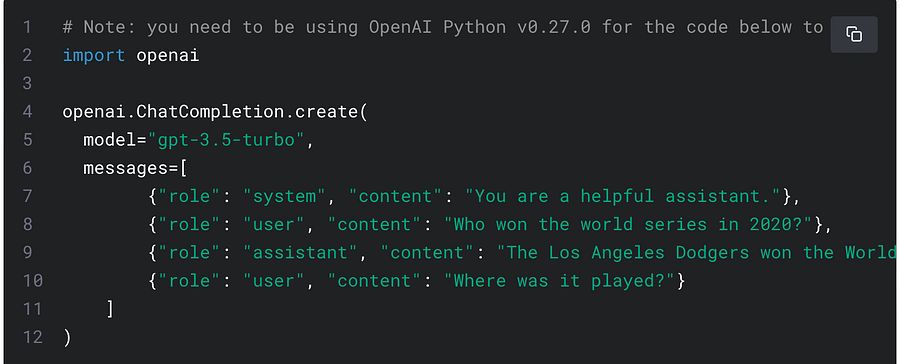
ChatGPT가 대화의 문맥을 기억하는 방법
ChatGPT를 어느 정도 사용해 본 사람이라면 ChatGPT와의 '대화' 를 통해서 좀 더 많은 정보를 제공하거나, ChatGPT의 출력에 대해 피드백을 주면 줄수록 보다 나은 결과를 얻을 수 있다는 것을 경험하였을 것이다. 그렇다면 어떻게 ChatGPT는 사용자와의 대화를 '기억'하고, 이를 통하여 더 나은 답을 제공할 수 있을까?
...
[학술 연구자를 위한 ChatGPT 활용] 1. ChatGPT의 출력을 어떻게 팩트 체크할 것인가?
[학술 연구자를 위한 ChatGPT 활용] 1. ChatGPT의 출력을 어떻게 팩트 체크할 것인가?
ChatGPT가 화제가 된지도 어느정도 시간이 지났고, 이제 ChatGPT 를 어떻게 생산적으로 사용할 수 있을지에 대해서 관심이 모아지고 있다. 그러나 ChatGPT 를 제대로 사용하기 위해서는, 흔히 ChatGPT에 대해서 가지는 여러가지 오해와 기능의 한계를 정확히 인식해야 한다. 가장 대표적인 오해라면 ChatGPT 를 ‘자연어 문장으로 검색 가능한 검색 엔진’ 으로 착각하는 것이다. 그러나 ChatGPT가 뱉어내는 결과들을 조금이라도 유심히 들여다 본 사람이라면 그렇지 않다는 것을 눈치챘을 것이다.
앞으로 몇 회에 걸쳐서, 연구자가 ChatGPT 를 활용하여 연구에 관련된 문서 (논문, 결과보고서, 과제계획서 등등) 를 작성할 때 주의해야 할 부분, 그리고 ChatGPT가 잘 하는 부분, 그닥 잘 하지 못하는 부분, 절대 ChatGPT를 써서는 안되는 부분에 대해서 알아볼 것이다. 그리고 이러한 한계를 극복하여 ChatGPT 등의 대규모 언어 모델 기반의 인공지능 ...
