






중심극한정리는 당신의 모집단을 마법처럼 정규분포로 바꾸어 주지 않습니다.

2023/01/07
사회과학에만 유령이 있는 게 아닙니다. 통계학에도 하나의 아주 악명높은 유령이 있습니다. 바로 중심극한정리라는 유령. 이 유령을 퇴치하기 위해 지금까지 수많은 통계학자와 데이터분석가가 덤볐지만, 끈질기게 죽지도 않고 살아납니다. 아니면 애초에 죽었으니 다시 죽일 수가 없는 것일까요. 그래서인지 여태 이 유령을 완전히 퇴치할 수는 없었습니다. 그래서 데이터분석을 하는 사람들은 주기적으로 되새겨야 합니다. 중심극한정리가 무엇인가를. 그래야 이 유령에게 홀리지 않을 수 있습니다.
아니, 사실 그 유령은 중심극한정리 그 자체가 아닙니다. 정확히 말하자면, 그 죽지도 않고 또 온 유령은 표본 크기가 충분히 크면, 중심극한정리에 의해 모집단이 정규분포를 따른다 입니다. 통계학에 조금의 관심이라도 있다면, 여러분도 이런 진술을 어디선가 봤을 것입니다. 이런 틀린 진술을. 제가 이 글을 쓰게 된 계기도 최근 이런 진술을 어디선가 또 봤기 때문입니다. 그것도 시중에서 꽤 잘 팔리고 있는 듯한 책에서 말이죠. 그 책 자체는 전반적으로 꽤 잘 쓴 책으로 보이고, 판매도 꽤 되고 있는 것 같습니다. 하지만 이 잘못된 명제 하나 때문에 저 같은 프로불편러의 역린을 건드려 버렸습니다.
이 글에서는 이 진술이 어디가 틀렸는지, 그리고 정확한 버전은 무엇인지 짧게 설명하겠습니다. 수식은 등장하지 않으니 걱정 안 하셔도 됩니다. 하지만 이 글에서 강조하려는 것은 이런 것들보다는 애초에 이런 오해가 왜 생기게 되었느냐 하는 것입니다. 사실 이것이 본질입니다.
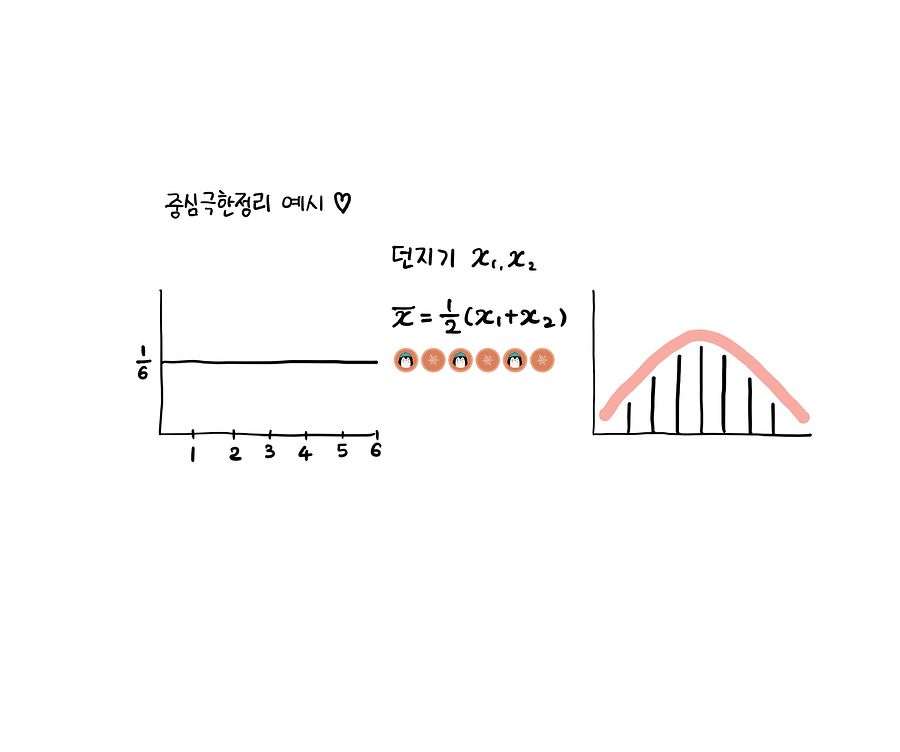
먼저 중심극한정리는 기본적으로 우리가 관심있어하는 집단 (모집단) 자체가 아니라 표집분포 또는 표본평균의 분포에 관한 명제입니다. 이 둘 (모집단의 분포 / 표집분포) 을 구분하지 못하는 것, 나아가 표본평균 같은 통계량이 그 자체의 분포를 가질 수 있다는 것 자체를 상상하지 못하는 것이 오해의 근본적인 원인입니다. 따라서 이 두 가지를 확실하게 구분하는 것이 중심극한정리에 대한 오해를 해결하는 첫걸음입니다.
우선 모집단입니...

심리학을 전공했지만 졸업 후에는 미국에서 데이터과학자로 일하고 있습니다. 데이터를 가지고 가치 있는 활동을 하는 데 관심이 많습니다. [가짜뉴스의 심리학], [3일 만에 끝내는 코딩 통계], [데이터과학자의 일] 등을 썼습니다.







.jpg)



본문의 내용을 시뮬레이션하는 사이트가 있는데, 저는 이 사이트를 통해 도움을 많이 받았습니다.
https://onlinestatbook.com/stat_sim/sampling_dist/index.html
잘 모르겠으면 그냥 하늘에서 표본평균 블록들이 후두두둑 떨어지는데 그게 가운데가 볼록한 모양으로 쌓인다더라 하는 이미지만으로도 오해를 없앨 수 있지 않을까 싶습니다. 저 같은 경우는 중심극한정리가 중요한 이유에 대해 '추론통계를 하고 싶다면 먼저 네가 이상한 표본을 재수없게 뽑았을 가능성부터 무마해야겠지? 근데 네가 뽑은 그 표본은 웬만하면 이상한 표본 아니니까 너무 걱정하지 말아라' 정도로 치고 넘겼습니다.
보통 고전적인 교과서에서 중심극한정리에 대한 설명을 시작하기 전에 모집단의 정의와 선정에 관한 설명이 들어가있는 단원이 있는데(그러나 제 기억력은 ㅆㄹㄱ…) 결과를 얻는 학습에만 집착(?)하고 사전 과정은 쉽다고 생략하는 경우가 많아서 그런 것이 아닐까요.
모집단에 대한 개념이 제대로 잡혀 있으면 오해하기도 어렵…
표본집단이 크면 모집단 분포가 정규분포인지 아닌지에 상관없이 통계량만으로 검정할 수 있다는 고리타분한 교과서 내용을 너무, 지나치게, 심각할 정도로 건너뛰는 게 아닐까요. =_=;;; 교과서가 무슨 죄……
정석 공부하라고 하면 공식 하나만 훑어본 후 공식 유도, 예제 다 건너뛰고 연습문제만 풀다가 실수로 몇 개 맞추고(?) 다 틀리는 격……
유익한 글 감사드립니다. 인문사회든 자연과학이든 현실에 존재하는 분포도 중 정규분포를 따르는 게 많다보니 오해가 가중되는 것 같습니다.
비슷한 오해로 흔히 '모평균이 신뢰구간 안에 포함될 확률'로 정의하는 사람이 많은 '표본평균의 xx% 신뢰구간'이 있지요.
모평균은 표본선정과 무관하게 '이미' 정해졌기에 가변적인, 확률적인 것처럼 기술하면 안 됩니다. 신뢰구간이 이미 정해진 이상 신뢰구간에 들어가거나 아니거나 둘 중 하나일 뿐.
'신뢰구간을 뽑았을 때 뽑힌 신뢰구간이 모평균을 포함할 확률'이 정답.
유령 맞습니다! 많이 봤어요ㅎㅎ
추측컨데... 표본 수(크기) 라는 표현이, 샘플 사이즈와, 샘플을 뽑는 횟수라는 중의적 해석으로 이어질 수 있기에 혼동이 발생하는 게 아닐까 싶습니다ㅎㅎ
유령 맞습니다! 많이 봤어요ㅎㅎ
추측컨데... 표본 수(크기) 라는 표현이, 샘플 사이즈와, 샘플을 뽑는 횟수라는 중의적 해석으로 이어질 수 있기에 혼동이 발생하는 게 아닐까 싶습니다ㅎㅎ
보통 고전적인 교과서에서 중심극한정리에 대한 설명을 시작하기 전에 모집단의 정의와 선정에 관한 설명이 들어가있는 단원이 있는데(그러나 제 기억력은 ㅆㄹㄱ…) 결과를 얻는 학습에만 집착(?)하고 사전 과정은 쉽다고 생략하는 경우가 많아서 그런 것이 아닐까요.
모집단에 대한 개념이 제대로 잡혀 있으면 오해하기도 어렵…
표본집단이 크면 모집단 분포가 정규분포인지 아닌지에 상관없이 통계량만으로 검정할 수 있다는 고리타분한 교과서 내용을 너무, 지나치게, 심각할 정도로 건너뛰는 게 아닐까요. =_=;;; 교과서가 무슨 죄……
정석 공부하라고 하면 공식 하나만 훑어본 후 공식 유도, 예제 다 건너뛰고 연습문제만 풀다가 실수로 몇 개 맞추고(?) 다 틀리는 격……
유익한 글 감사드립니다. 인문사회든 자연과학이든 현실에 존재하는 분포도 중 정규분포를 따르는 게 많다보니 오해가 가중되는 것 같습니다.
비슷한 오해로 흔히 '모평균이 신뢰구간 안에 포함될 확률'로 정의하는 사람이 많은 '표본평균의 xx% 신뢰구간'이 있지요.
모평균은 표본선정과 무관하게 '이미' 정해졌기에 가변적인, 확률적인 것처럼 기술하면 안 됩니다. 신뢰구간이 이미 정해진 이상 신뢰구간에 들어가거나 아니거나 둘 중 하나일 뿐.
'신뢰구간을 뽑았을 때 뽑힌 신뢰구간이 모평균을 포함할 확률'이 정답.