






빅테크는 왜 안면인식기술을 경찰에 판매하지 않을까?

2021/10/29

정부가 출입국 심사 및 이상행동감지를 위한 인공지능 개발을 추진하면서, 법무부가 보유한 내·외국인 얼굴 사진 1억7천만건을 민간 업체가 사용할 수 있도록 했다는 한겨레 보도(10월 21일)가 있었습니다. 이 글에서는 이 정부추진사업의 개발 목표인 안면인식기술이 최근 몇 년 간 (특히 미국에서) 논란이 된 맥락을 간단히 설명하려 합니다.
어떤 기술을 만드는 사업인가요?
우선 법무부와 과기부에서 추진하고 있는 사업의 이름은 '인공지능 식별추적 시스템 구축 실증 및 검증'입니다. AI식별추적시스템의 목표는 크게 안면인식과 이상행동감지로 나뉩니다.
1. 안면인식
안면인식(facial recognition)은 얼굴 데이터를 사용하여 사람이 누구인지 맞추는 일이며, 다시 두 종류의 과업으로 나눠 생각할 수 있습니다.
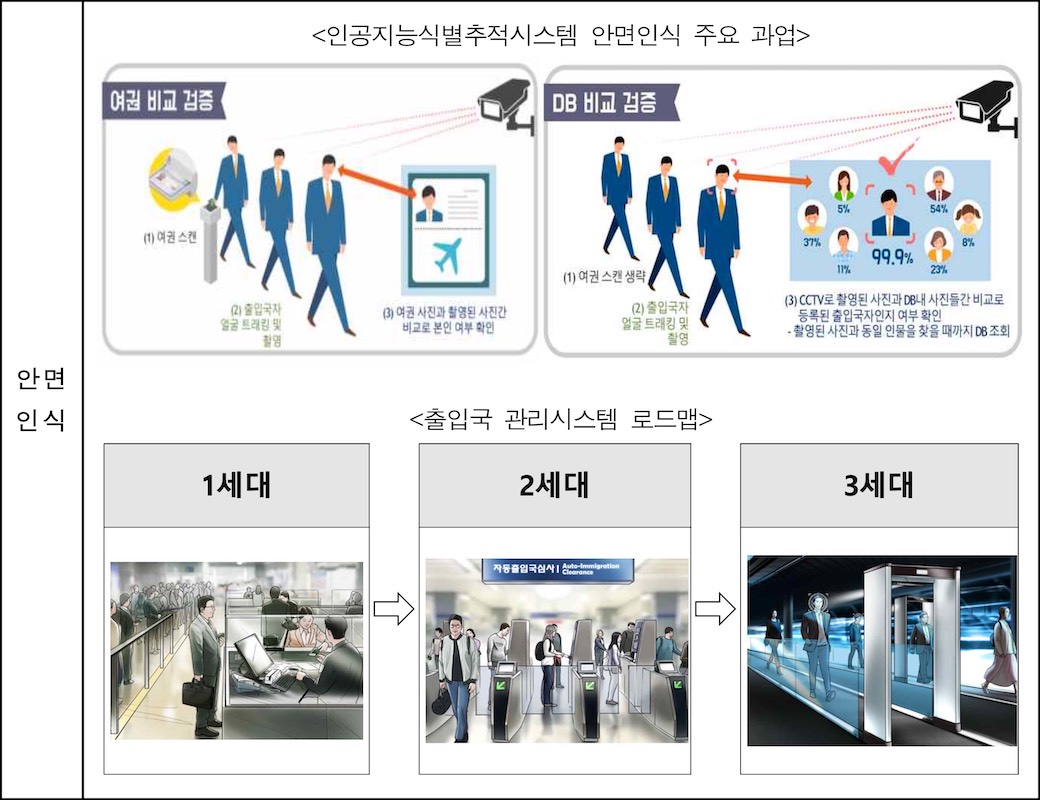
- 1:1 매칭: 지점A(예: 여권 스캔)에서 찍은 얼굴이 지점B(예: 입국심사대 CCTV)에서 찍은 얼굴과 동일인물인지 여부를 판별합니다. 스마트폰의 페이스 ID도 이렇게 작동합니다.
- 1:N 매칭: 한 지점(예: 입국심사대 CCTV)에서 찍은 얼굴이 DB에 이미 등록된 여러 얼굴 중 어떤 인물과 일치하는지 판별합니다. 보통 이것을 '식별(identification)'이라고 부릅니다. TV 수사물 보면 용의자 사진을 경찰이 보유한 범죄자 사진과 대조해주는 시스템이 종종 나오죠? 그런 개념입니다.
이번 사업에서 만들고자 하는 것은 가만히 서서 찍은 사진, 움직이는 영상, 혼자 또는 많은 사람이 찍힌 경우 등 여러 상황에서 위의 매칭 작업을 정확하게 처리하는 시스템입니다. 이를 위해 법무부와 과기부는 한국인 중 자동 출입국 심사 신청자 얼굴 사진 5760만장, 외국인 얼굴 사진 1억2000만장을 선정 업체들...














.jpg)


